I’m an end-to-end data specialist with 10+ years building production systems across fintech, insurance, HR tech, and data governance. I’ve led teams, architected pipelines, and shipped products—from document AI systems processing thousands of files to ML models that identified startups before they went public.
My academic work on Bayesian methods and causal inference has been cited over 1,750 times. I hold a PhD in Statistics from Warwick and a BA in Mathematical Sciences from Oxford.
Based in Tel Aviv. Loves data, coffee, and the Oxford comma.
Open to contract, consulting, part-time, and full-time opportunities.
Whether you’re building something new or have a stuck project that needs rescuing, get in touch.
What I Do
I help organisations build and fix production data systems—from initial architecture through to deployment and handover.
Typical engagements include:
- Data pipeline architecture and engineering — Python, SQL, dbt, Airflow, Snowflake, Databricks. I’ve built document AI systems that process 500+ files in 20 minutes with 95%+ accuracy.
- Machine learning in production — From startup detection models for VC deal sourcing to anomaly detection for enterprise data governance.
- LLM integration — Claude, GPT, Gemini. Early adopter (GPT-3 era) with production deployments.
- Team leadership and mentoring — Hiring, architecture decisions, code review, unblocking stuck projects.
I’ve worked across fintech, insurance, HR tech, venture capital, and civic tech—so I’m comfortable translating between business stakeholders and technical implementation.
Featured Project

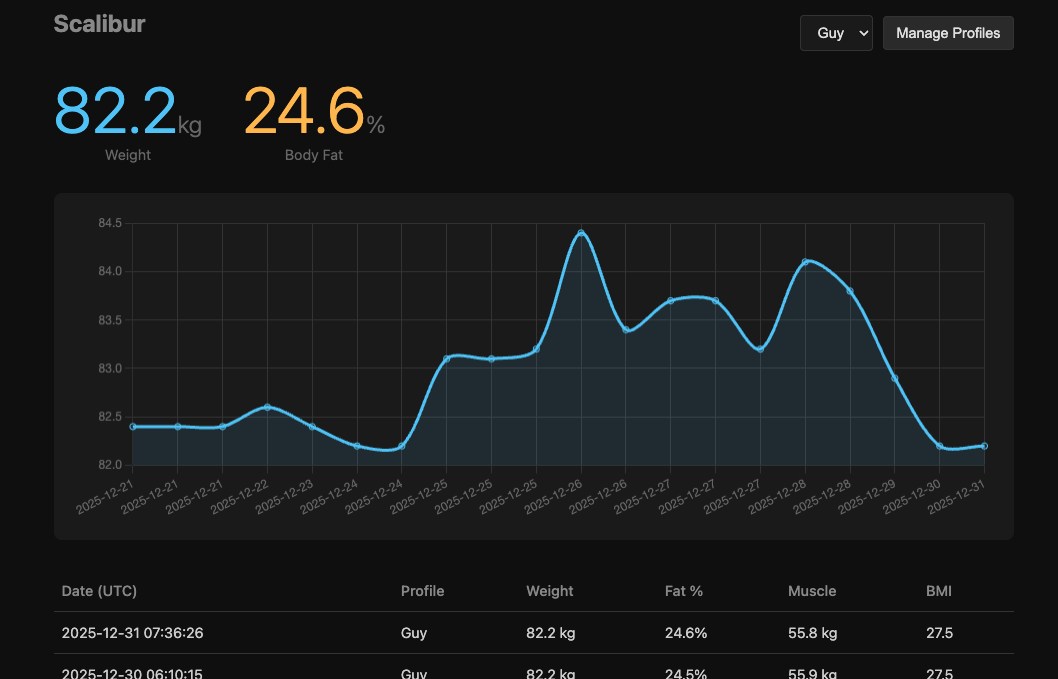
Scalibur
Python tool for reading body composition data from cheap Bluetooth scales. Reverse-engineered BLE protocol, handles impedance measurements, and calculates body fat, muscle mass, and metabolic metrics.